 From the Real to the Unreal: A New Work Exploring Cross Species Spectral Morphing
From the Real to the Unreal: A New Work Exploring Cross Species Spectral MorphingIntroduction
From the Real to the Unreal is a new work which explores the morphing and synthesis of two sound sources. These sounds gradually exchange their spectral maps over the course of an hour, creating a gradual shifting of each others harmonic characteristics,
i. e. example 1:
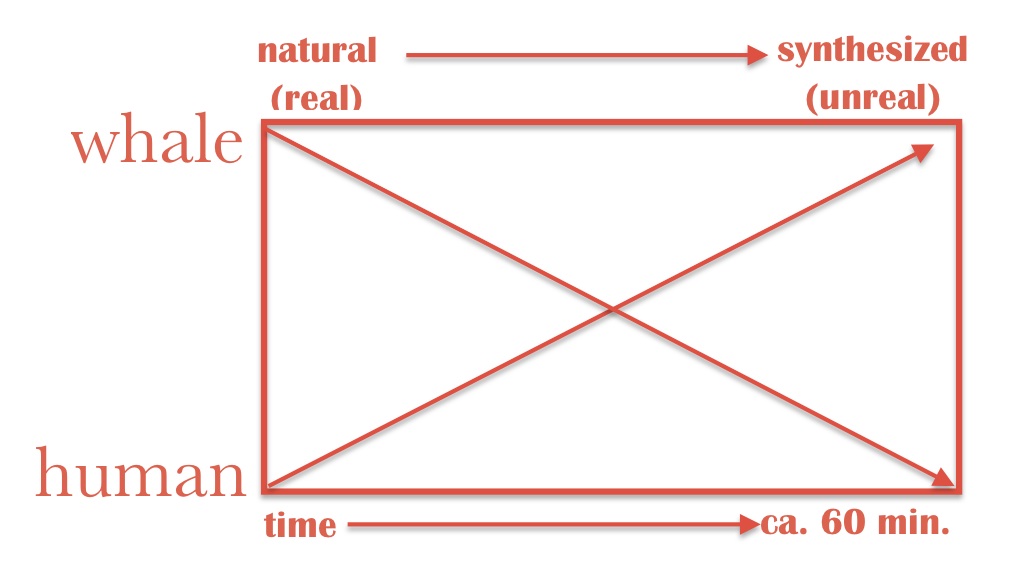
Example 1
As the work progresses, sound source A gradually comes to embody the spectral characteristics of sound source B without altering its source. The same procedure is undertaken on sound source B. In effect, there is a gradual movement of each source away from its authentic characteristics to an imitation or synthesizing the opposite source.
The title refers to a portion of a prayer from Hatha Yoga practice, “Asatho Maa Sath Gamaya,” meaning “Lead me from the unreal to the Real.”(1) The work attempts the opposite–moving from the Real to the unreal. It is intended as a reflection on the contemporary prevalence of the un-natural and a commentary on our highly synthesized global environment. If, as Satchidananda suggests, moving from the unreal to the Real might help one “shine as fully developed Yogis, radiating joy, peace, and knowledge everywhere,” then a shift towards the unreal might provoke the opposite.(2)
Sound Sources
Key aspects of this project includes the connections between humans and the natural world. To emphasize these connections, the sound sources chosen are human (spoken text) and animal (humpback whale) sounds. The text, “Time is a snake that eats its own tail” refers to the cyclical nature of time and the ancient Ouroboros. The whale sounds are from Capitol Record’s 1970 LP “Songs of the Humpback Whale. The project began with an analysis and exploration of each source. The following sections deal with the human voice and the components of the text, followed by an investigation into two types of whale sounds.
Vowels
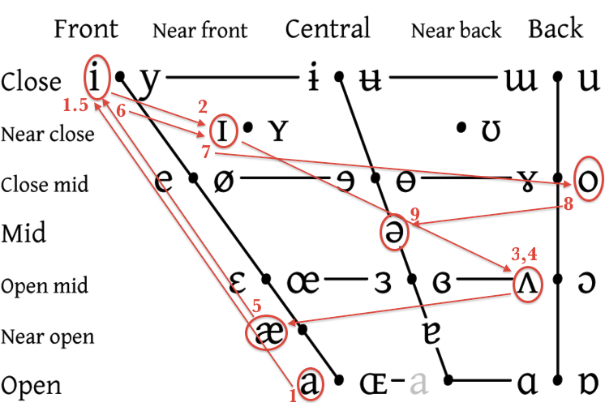
The human voice produces vowels by vibrating the vocal chords without any closure of the vocal tract by the glottis. This creates a sound with consonant partials (spaced by integer multiples) with defined fundamentals. The qualities of the vowel are determined by the size and shape of the vocal cavity. Vowels are classified by the location of their predominate resonance. Example 11 is the vocal quadrangle, which gives an approximate placement of many vowels within the vocal cavity (the vowels utilized in the text are highlighted).
The horizontal arrangement of vowels along the cavity is classified as “back” to “front” in relation to the back of the throat to the top front teeth. Likewise, the vertical placement of the jaw is classified as “close” (with the jaw shut and the tongue obstructing the sound) to “open” (with the jaw dropped and the tongue not obstructing the sound). Diphthongs are formed by moving from one vowel shape to another; triphthongs contain three successive vowel sounds. Vowels can be classified as “rounded” or “unrounded” depending on the shape of the lips.
Consonants
Consonants are produced by obstructing the vocal cavity above the glottis with the tongue, teeth, or other methods. Some consonants (namely b, d, g and v) resonant vocal chords and are called “voiced;” others (p, t, k, f, s) are “voiceless” and formed in the front of the mouth. Consonants are classified by their manner of articulation.
Fricatives are produced by forcing air through a passage closed in some way, usually by the tongue or the teeth. The passage of air through this closed passage creates friction as a result and produces sounds with densely dissonant formant regions. Affricatives begin as a fricative and then move quickly to open the vocal cavity into a vowel sound (as in “ch” or “j”). Plosive describes consonants where airflow is released through the mouth; implosive refers to consonants where air is inhaled. A vocal stop occurs when the airflow is stopped by the tongue or teeth (such as with “p,” “t” and “k.”)
Aspirates are characterized by an outward pushing and rushing of air through the open vocal cavity (as with “h”). Sibilants are “hissing” sounds produced by fricative action with a closed vocal cavity (“z”). Gutturals occur at the back of the throat with the tongue moving towards the soft palate near the glottis (“g”). Palatals are formed by moving the tongue up towards the hard palate (“r”). Dental consonants utilize the back of the teeth (“t”). Lateral consonants use the tongue to block the flow of air through the center of the mouth, producing an “L” sound. Nasal consonants are articulated primarily in the nose and sinus cavity. Labials (“b” or “p”) utilize the lips for articulation; labio-dentals utilize both the lips and the teeth (“v,” or “f”).
Time
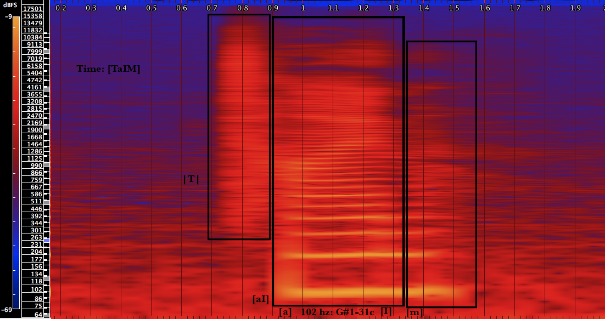
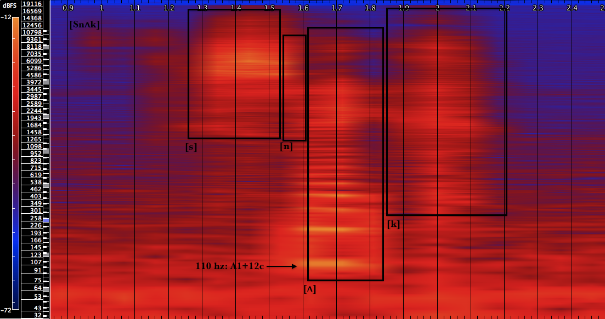
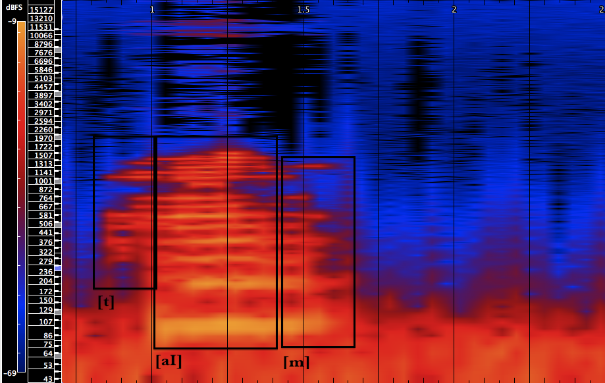
[T] from “time” is an unvoiced dental consonant formed by both the build up and release of air pressure (a plosive). It is formed with the tongue above the upper gum line and ridge (alveolar). Pitch is limited; frequencies are scattered beginning near 441 hz with relative harmonic density around 1119 hz and higher.
[aI] is a diphthong; it moves from one vowel placement to another ([a] to [I]). we can see from example 2 how the frequency focus becomes clearer and the visible overtones become stronger and more pronounced as the voice moves from [a] to [I]. Its basic fundamental frequency in this example is near 102 hz (G#1-31c).
[m] is a nasal consonant. Nasal consonants are formed from complete oral closure. The sound is forced out through the nasal passage. The effect seen in example 2 is of a slight raise in pitch, the dissipation of the overtones that were prevalent in [aI] and a subtle widening of the frequency bandwidth.
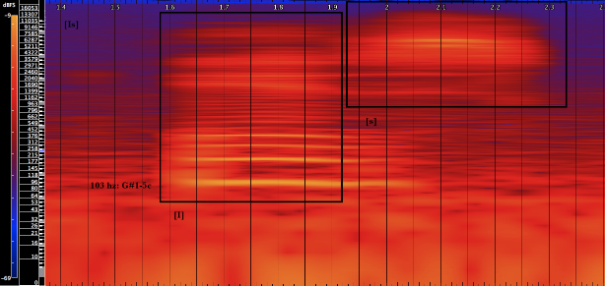
Is
[I] is a near closed and near front unrounded vowel. This means the tongue is positioned near the front, positioned less constricted than a close vowel and it is produced with unrounded lips. On this example, the fundamental frequency of this vowel is almost the same as the previous example, 103 hz.
[s]is a dental formed by moving the tongue towards and against the upper teeth. Like [t], another dental, it is rich in harmonics and has indefinite pitch. In this example, there are strong frequencies near 5000 hz. Unlike [t], it is a fricative, formed from the outward flow of air being partially blocked by the tongue.
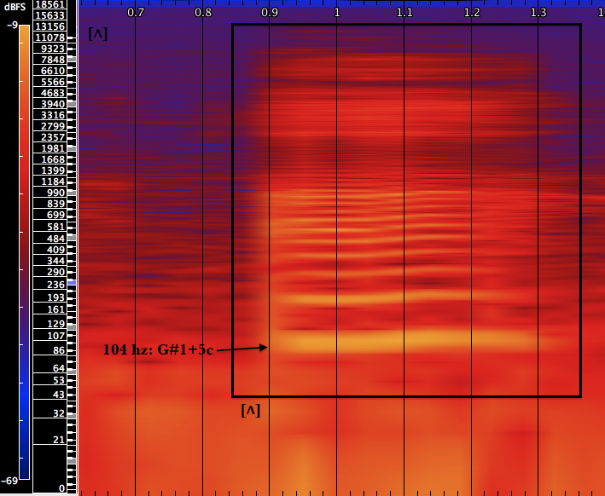
A
[ʌ] is an open mid vowel with the tongue halfway between an open vowel and a mid vowel. The tongue is positioned far back in the mouth so as to not create an obstruction. It is an unrounded vowel (the lips are not rounded). The fundamental frequency of this example is also 104 hz.
Snake
[s] (dental fricative) described above (example 3). Lacking definite pitch, this [s] has a high concentration of frequencies occurring around 5000 hz (see example 5).
[n] is a nasal consonant (like [m]), produced by placing the tip of the tongue against the upper gum behind the upper side teeth. It is approached seamlessly from [s]; example 5 shows how [s] and [n] are connected around 5000 hz. Moving from [s] to [n] shows a reduction in the frequency bandwidth.
[ʌ] (open mid vowel) described above (as in example 4). In the case of example 5, the peak fundamental frequency is slightly higher than example 4, around 110 hz.
[k] is a guttural consonant, the voiced equivalent of [g]. It is produced by the action of the back of the tongue against the point where the soft and hard palates meet. This contact produces implosion, plosion, explosion and also fricative action. The result lacks definite pitch and has a wide bandwidth encompassing frequencies between 40 hz up to at least 4,500 hz.
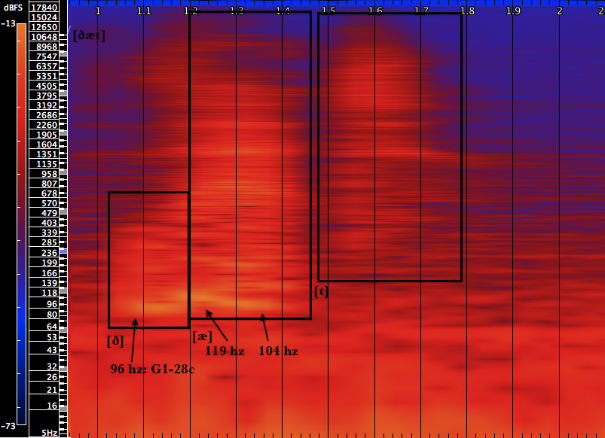
That
[ð] is a dental consonant that occurs from partial implosion with the tongue slightly touching the upper teeth. This consonant is slightly pitched with a fundamental frequency near 96 hz (see example 6).
[æ] sees the pitch rising slightly, near 119 hz, dropping down to 104 hz. For this vowel, the tip of the tongue remains in contact with the lower gum line and the rest of the tongue follows the downward motion of the jaw. It is a fairly resonant vowel.
[T] is described above (as used in “time,” example 2). It does not have a definite pitch; it is a cluster of frequencies, in this case between ca. 130 and ca. 17840 hz.
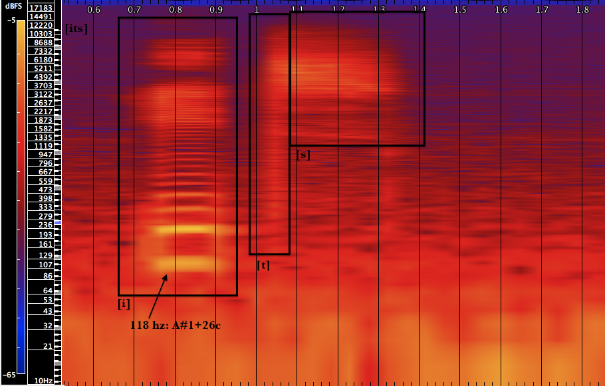
Eats
[i] is considered to be the furthest front vowel, meaning that it is articulated with the highest point of the tongue arching towards the front of the mouth, below the hard palate. It is a closed vowel, with the airway obstructed by the back of the tongue. In example 7, the fundamental frequency is near 118 hz.
[t] is described above (as used in “time,” example 2). In example 7 it is a short sound that is passed between [i] and [s]. As an non-pitched consonant, it shows a higher frequency content than [i] and lower than [s] in this example.
[s] is described above (as used in “is,” example 3). In example 7 it is also a non-pitched cluster of frequencies strong near 5000 hz.
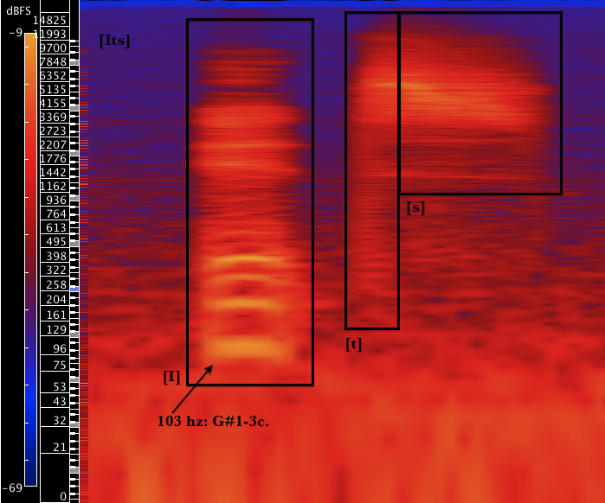
Its
[I] is discussed above with example 3. It is similar to the [i] of “eats” but involves dropping the jaw slightly. In this example it has a strong fundamental frequency near 103 hz.
[t] and [s] are both discussed above (as used in “Time,” “Snake” “That” and “Eats”). The usage here is the same as in example 7: [t] moves quickly to [s], the next consonant. In both cases [t] is rather short compared to [s] which is longer and higher in general frequency.
Examples 7 and 8 are very similar, differing in the overtone structure of the first vowel. This is a result of dropping the jaw slightly more for [I].
Own
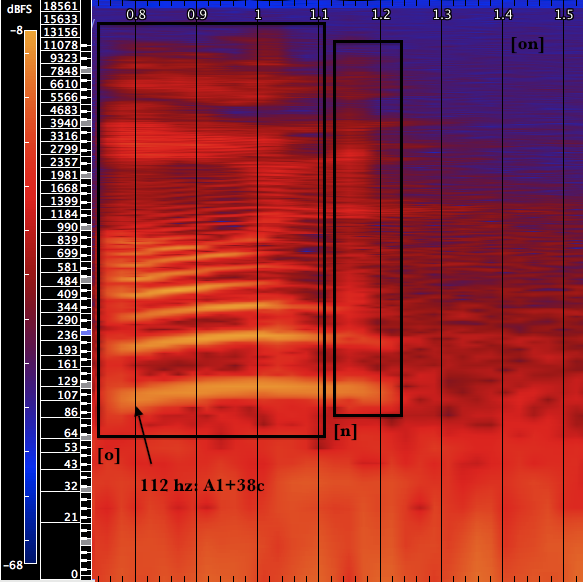
[o] is a back and mid-closed vowel made with rounded lips. In example 9, it has a strong fundamental frequency near 112 hz, which glissandos up around 10 hz to [n].
[n] is a closed nasal similar to [m] from “time” (example 2). Implosion occurs behind the tongue. Pitch is prevalent and connected to [o]; [n] sees a reduction in well defined overtones. The sound is made as in humming.
Tail
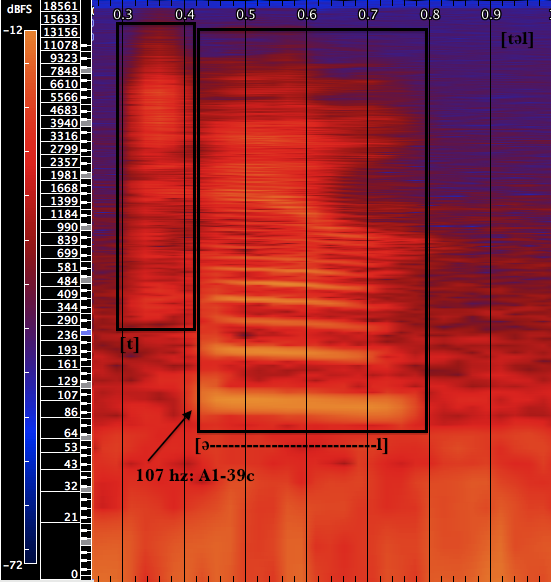
[t] is described above (as used in “time,” example 2). In this case (example 10) the frequencies are between ca. 300 and 18,000 hz.
[əl] combines the schwa sound [ə] with the dental consonant [l]. As can be seen from example 10, the strata between the two sounds is blurred; [l] falls at the end of the sound but is subtly added to the [ə] sound. This is achieved by slightly dropping the jaw and pushing the lips slightly further out.
As mentioned above, the text was chosen because of the interesting manner in which it moves through various phonemes. See example 11 which traces the physical vocal placement of vowels through the sentence. This chart shows the relative placement of the vowel in the vocal cavity. The first vowel, the diphthong [ai] begins is low, near front and open on [a] and closes to the [i]. [I] is near front and the next two vowels, [ʌ] of “snake” and “that” are open but towards the back. [æ] of “eats” is near front and near open, with the jaw dropped. “Its” and “own” have the same motion as from the dipthong [ai] in “time” to the [I] of “is.” The [o] of “own” is unique in this text; it is farthest back vowel and in a close mid position. The schwa of “tail” closes the sentence in a central-mid location.
Whale Sounds
Nine Humpback Whale sounds were chosen as a compliment to the previously analyzed text. The calls are taken from a 1970’s LP, Songs of the Humpback Whales. Humpback whales are capable of a variety of sound, often described as “whistles, whines, squeals, screams, squeaks, clicks, moans, hums, growls, bellows, roars, etc...” (3) Due to their massive body size, many Humpback Whales are capable of producing tones below the range of human hearing, known as sub or infrasonic frequencies. (4) The frequencies perceived by human ears seem to suggest deep sub-frequencies that provide a fundamental for long, clear sounds in the upper frequencies. The recording suggests that the Whale’s technique is that of “whistling” through the higher parts of a fundamental’s overtone series by subtly emphasizing different harmonic nodes. (5) Example 12 shows one type of “whistled” whale sound from the recording that was utilized. (6)
Humpback Whale “Whistles”

Example 12 shows one type of sound that is characteristic of the majority of sources utilized for spectral morphing in this project. It is characterized by long, clear tones that rise towards their end.7 The strongest and lowest frequency represented here wavers near 360 hz., with many strong upper partials logarithmically spaced above this frequency. The pitch is relatively constant for almost two seconds, at which point the sound glissandos upwards slightly. The next example examines this occasion with a closer view:
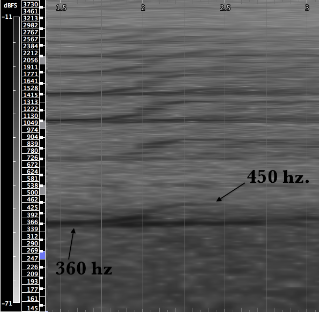
Example 13: close up view of the same whale sound, 1.5–3 seconds.
The lifting sound represented in example 13 is highly characteristic and frequently occurs on the end of long tones. The lift in the lowest frequency is around 90 hz. (ca. 360 to 450 hz.) and occurs while the original tone reverberates as the sound echos off of the ocean floor. The effect is that of an vertically opening wedge shape where one frequency remains constant and another rises upwards from it. Each version utilized in this project of this sound is unique and particular; frequency levels vary, as does the relative amplitude levels of various formant areas within the overtone structure.
Humpback Whale “Growls”
A second type of whale sound utilized for morphing in this project might be described as a low growl. Example 14 shows one such type; there are no clear single frequencies but instead two formant regions around 53 and 200 hz. The sound is a low rumbling sound, suggestive of a giant cat’s purr.

Example 14: six seconds of a Humpback Whale “Growl.”
Because the formant regions are so dense, it is unclear from example 14 what the central frequencies of the formant regions might be. Another analysis (example 15) of a smaller sample shows the strongest (peak) frequencies for the formant region. The lowest activity is near 56 hz, with higher, denser and louder sounds between ca. 100 and 250 hz:
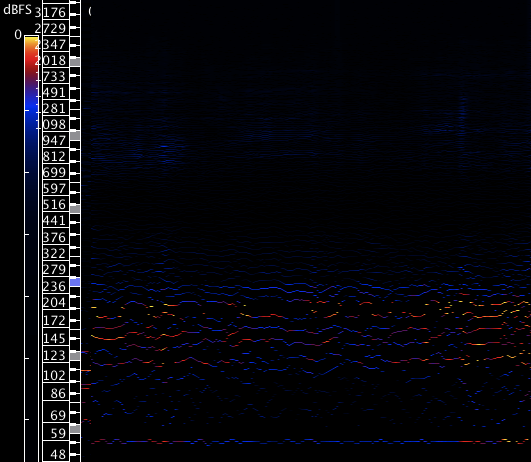
Examples 12–15 show two distinct sounds that Humpback whales are capable of, sometimes called “whistles” and “growls.” These sounds are highly contrasting. “Whistle” sounds utilize long, clear frequencies with defined partials and a portamento glide towards their end; “growls” have denser formant regions where definite pitch is not as clear. This could be considered synonymous with the contrast between vowels and consonants in human speech. Like vowels, whale whistle sounds have strong fundamentals with upper partials seemingly spaced at integer multiples. This produces specific pitches and a clear timbre in both vowels and “whistles.” Growls, like consonants, have clusters of frequencies within formant areas where the fundamental frequency is wavering and the upper partials are not precisely spaced by integer multiples. Because of this, the sounds lack specific pitch and are perceived as closely spaced clusters of frequencies.
Spectral Morphing
To turn both human speech to whale sounds and vice-versa, sounds were first compared for distinctive features (as detailed above). Morphing was accomplished by transposing each source sound to close to the fundamental frequency of the sound to be morphed with. The sounds were then lengthened (without changing their pitch) to a time comparable to the morph destination. Next, spectral morphing software was used to influence the amplitude of overtone partials. This procedure shifted the the spectral content of the source sound to resemble that of the sound being morphed to. This changed the timbre of the source sound to resemble that of the morph destination. The goal is not a “cross-fade” technique, where one sound gains amplitude while another fades out.8 Rather, the goal is the transformation of one sound to resemble certain characteristics of another. The following sections detail a few examples of the morphing procedures.
Human Speech to a Whale “Whistle”
To morph the word “time” to embody the audible characteristics of a Humpback Whale “whistle,” it was first transposed from its fundamental frequency of ca. 102 to the fundamental of the chosen whale whistle, ca. 370 hz.
Example 16: “Time” original.

Example 17, “Time” transposed to 370 hz.

Example 18: “Time” after being transposed and lengthened is morphed with the whale source from example 19.
The morphing technique employed does not add additional frequencies or dramatically reshape the original sound past a certain extent. The technique finds those frequencies that the two sounds have in common and adjusted the amplitude level of the partials of the source to meet that of the morph destination. This differs from the technique of “cross-fade” which increases the amplitude of one source while decreasing that of a second.
Human Speech to a Whale “Growl”
To morph human speech to a Whale “growl,” this peak frequency spectrograph of one such whale sound was considered (example 20):
Example 20: Peak Frequencies for a Humpback Whale “Growl.”
The word “That” worked well to morph to a growl. This could be because the dental consonants [ð] and [t], as well as the the vowel [æ] all have rather undetermined pitch and dense formant regions (see example 21). Also, on the recording, the speaker had a “frog in his throat” which disturbed the sense of absolute pitch clarity.
The frequency of “That” was shifted to 207 hz. to arrive close to a central formant frequency of example 19. This was lengthened and morphed to the following result (example 22):
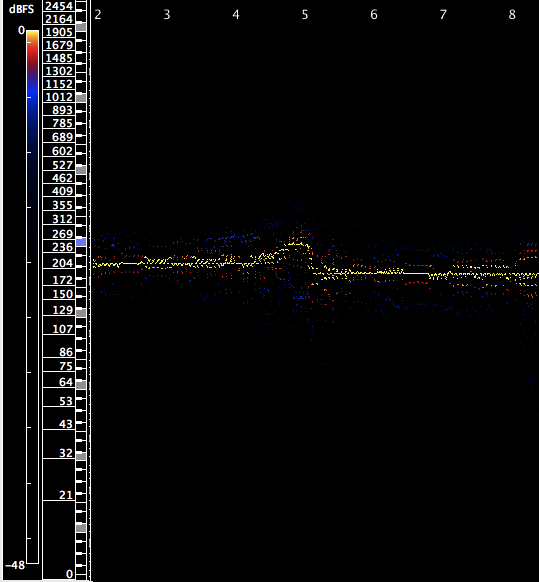
The morphing process filters the spectral content to a similar frequency band as in example 20; frequencies are strongest between 100 and 250 hz. with a peak frequency meandering through the centre of the formant area. The result is a low, growling sound that whose absolute pitch definition is obscured by the multitude of simultaneous frequencies.
Whale “Whistles” to Human Speech
The opposite procedure to that discussed above was undertaken to morph whale sounds to reflect the spectral characteristics of human speech. Whale sounds were transposed to the general frequency area of human speech and then morphed to conform the whale sound to that of human speech. Examples 23 gives a whale “whistle” sound; example 24 shows the word “time” that the whale sound will be morphed to imitate.
Example 24: the word “Time.”
[aI] is represented as a more resonant phoneme, with clear frequencies that are similar in shape and amplitude through their partials as in example 24. The final [m] sound is represented in the morphed version in a slight lift in frequency and a lowering of the amplitude of certain partials. This slight lift is also characteristic of the source text (example 24).
A Man Whistles and Growls Like a Whale
Example 26 shows all nine words of the text “time is a snake that eats its own tail” morphed to resemble whale sounds. Each word but “that” was morphed with a “whistle” type whale sound at varying frequencies. A connection between the morphed human source and whale sound is apparent; the human text is reduced to long tones. Consonant formant areas are generally filtered out but some remain; [s] and [t] sounds especially are retained. The clarity of the transformed vowels approximates the fundamental and lower partials of the whale sounds. The “growl” on the fourth word, “time,” is represented by a lower, denser frequency area than the rest of the sounds. Background noise is morphed as well, complicating the lower spectrum.
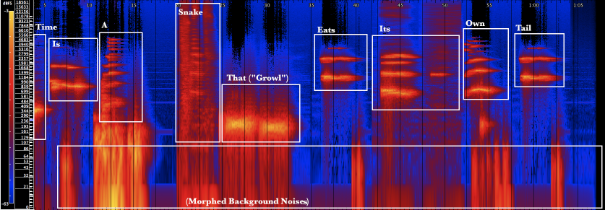
A Whale Speaks Prophetically About Time
Example 27 shows the entire text being emulated by morphed whale sounds. All the source whale sounds were “whistle” type sounds, except for the word “that” which was morphed from a “growl” sound. A relationship between the original text is apparent; the inflection of partials is similar to the shape of each individual word. The whale sound is not capable of producing a perfect morph, as the clear whale “whistle” sounds do not contain the complex formant areas that define consonants. Even still, by morphing to a general shape of the spectral structure creates a convincing and comprehensible result.
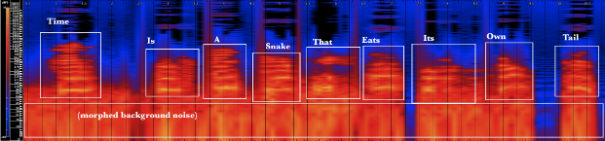
Conclusions
The goal of this project was never to totally reverse two sounds; this could be done simply with cross-fading two sound files with each other. Rather, the goal was to take each sound source and alter it so that its spectral characteristics embodied on some level those of another sound. The “speaking whale” or the “human that whistles like a whale” do not sound exactly like their morph sources, nor are they intended to. Rather, the goal was to experiment with the sounds to see what similarities between human and animal sounds might be discovered.
The end results show that human vowels are easily conformed to sound like whale “whistles” when having their partials adjusted once being transposed and lengthened. Consonants are more closely related to whale “growls” which contain complex formant areas recognized as dissonant or noisy spectral areas.
In turning whale sounds to emulate human speech, all that is necessary is matching the fundamental frequencies and then filtering out those partial frequencies that are not part of the human speech. The process is like “drawing by erasing what is already there;” by removing those extemporaneous parts of the harmonic spectrum that are absent from a source sound and emphasizing (or de-emphasizing) partials in reflection of the morph destination, a convincing imitation can be created.
Notes:
1 Sri Swami Satchidananda, Yogiraj. xxix
2 Ibid.
3 Tinker, 84.
4 Tinker, 84.
5 See Doolittle.
6 Taken from Songs of the Humpback Whale, side 1, band 1, “Solo Whale.” This source for whale sounds is purposeful; it adds another layer of metaphorical distance between the real (real whale sounds as experienced by whales in the ocean) and the un-real (a digitized version of a scratchy LP, dug out of the music library shelves at Bennington College).
7 The continuous sounds near 53 hz. and below on several examples is background sound from the LP itself. If any of the whales recorded sang in sub tones, they are not reproduced on these recordings. The whale sounds utilized in this project show clear frequencies between near 270 and 1000 hz. It is likely that one or more fundamental tones are not represented. This possibility was not considered in the process of spectral morphing; the recording was taken “as is” and utilized as a found object.
8 See Truax, 28.
Bibliography
Doolittle, Emily. “Crickets in the Concert Hall: A History of Animals in Western Music.” Revista Transcultural de
Música Transcultural Music Review #12, 2008. http://www.sibetrans.com/trans/trans12/art09.htm
Hall, Donald E. Musical Acoustics: An Introduction. Belmont, CA: Wadsworth Publishing Company, 1980. Print.
Lowery, H. A Guide to Musical Acoustics. London: Dennis Dobson, 1969. Print.
Payne, Roger S. Songs of the Humpback Whale. Hollywood, CA: Capitol Records, 1970. LP.
Pierce, John R. The Science of Musical Sound. New York, NY: Scientific American Library, 1983. Print.
Pfautsch, Lloyd. English Diction for Singers. New York, NY: Lawson-Gould Music Publishers, Inc., 1971. Print.
Roederer, Juan G. Introduction to the Physics and Psychophysics of Music. New York, NY: Springer-Verlag, 1975. Print.
Satchidananda, Yigiraj Sri Swami. Integral Yoga Hatha. New York, NY: Holt, Rinehart and Winston, 1970. Print.
Tinker, Spencer Wilkie. Whales of the World. Honolulu, HI: Bess Press, 1988. Print.
Truax, Barry. Ed. Handbook For Acoustic Ecology. No. 5 in “The Music of the Environment Series,” R. Murray Schafer, Series Editor. Burnaby, B.C.: World Soundscape Project, 1978. Print.
Weyler, Rex. Song of the Whale Garden City, NY: Anchor Press, 1986. Print.